🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
데이터 분석을 위한 임팔라, 제플린, 머하웃을 사용해 보고, 스쿱을 이용하여 분석 데이터를 저장 해 볼 것이다.
⭕ 임팔라 추가
◼ 클러스터 - 서비스 추가 - 임팔라를 선택

설치될 서버(server02)를 선택한다.

❓ Impala Daemon 스크래치 디렉토리란
쿼리 실행 시 생성되는 임시파일을 저장하는 위치이다.

임팔라는 휴와 연동이 되어있으니
◼ Hue - 구성 - Impala 검색 후 설정 해주고 저장.
◼ 임팔라 재시작.
◼ Hue 재시작.


⭕ 스쿱 추가.
◼ 클러스터 - 서비스 추가 - 스쿱

◼ 서버 선택(server02)

이후 재 배포를 해 주어야 한다.
⭕ 제플린 추가.
제플린은 Cloudera 에서 지원을 하지 않아 서버에 직접 다운받아 줄 것이다.
◼ server02 에 아래 실행.
cd /home/pilot-pjt
wget http://archive.apache.org/dist/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgz
◼ 압축풀기
tar -xvf zeppelin-0.8.2-bin-all.tgz
◼ link 걸기
ln -s zeppelin-0.8.2-bin-all zeppelin
◼ 제플린 구성정보 변경을 위한 폴더 이동
cd /home/pilot-pjt/zeppelin/conf
◼ template 파일을 가지고 복사
cp zeppelin-env.sh.template zeppelin-env.sh
◼ vi 접속
vi zeppelin-env.sh
◼ 다음 내용을 추가
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export HADOOP_CONF_DIR=/etc/hadoop/conf
◼ hive 임시 디렉토리를 제플린이 사용하도록 권한변경
chmod 777 /tmp/hive
◼ 제플린에서 hive interpreter를 사용하기 위해 hive 설정파일을 복사
cp /etc/hive/conf/hive-site.xml /home/pilot-pjt/zeppelin/conf
cd /home/pilot-pjt/zeppelin/conf
cp zeppelin-site.xml.template zeppelin-site.xml
◼ 내용을 수정한다
vi zeppelin-site.xml 1.zeppelin.server.addr 변경
127.0.0.1 => 0.0.0.0
2.zeppelin.server.port 변경
8080 => 8081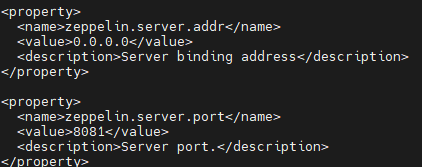
◼ 해당 파일에 아래 내용 추가.
vi /root/.bash_profilePATH=$PATH:/home/pilot-pjt/zeppelin/bin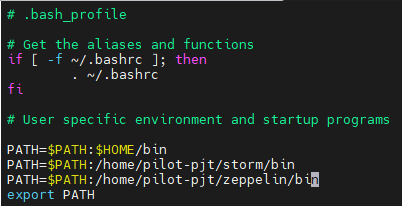
◼ 변경 내용 즉시 적용
source /root/.bash_profile
◼ zeppelin 실행
zeppelin-daemon.sh start
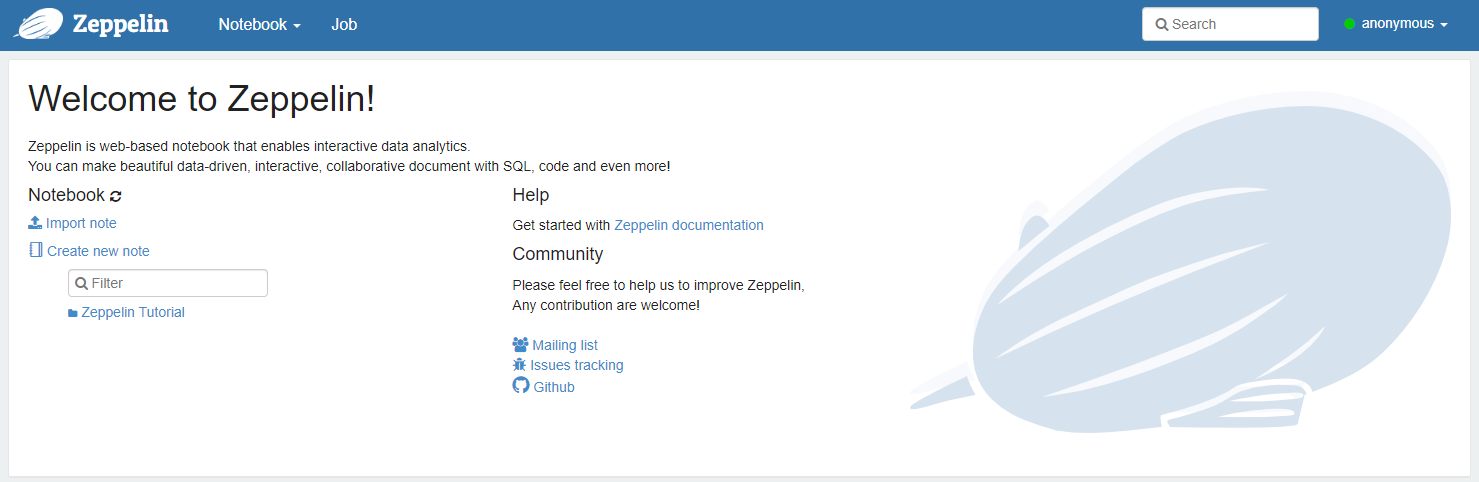
◼ zeppelin url 실행 (자신의 서버와 포트번호)
http://server02.hadoop.com:8081
⭕ 머하웃 추가
❓ 머하웃이란
대용량 데이터를 처리하는 기계 학습용 라이브러리
◼ 아래 위치로 이동해서 파일 다운
cd /home/pilot-pjt
wget http://archive.apache.org/dist/mahout/0.13.0/apache-mahout-distribution-0.13.0.tar.gz
◼ 압축해제
tar -xvf apache-mahout-distribution-0.13.0.tar.gz
◼ link 걸기
ln -s apache-mahout-distribution-0.13.0 mahout
◼ 패스 내용추가를 위한 파일 열기
vi /root/.bash_profilePATH=$PATH:/home/pilot-pjt/mahout/bin
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera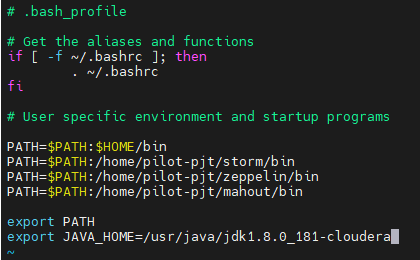
◼ 패스 적용
source /root/.bash_profile
◼ 머하웃 실행
mahout
'빅데이터' 카테고리의 다른 글
| [빅데이터] 제플린 사용해 보기. (0) | 2024.06.18 |
|---|---|
| [빅데이터] Impala 사용해 보기. (2) | 2024.06.18 |
| [빅데이터] Oozie Workflow (0) | 2024.06.17 |
| [빅데이터] Oozie 사용 해 보기. (4) | 2024.06.14 |
| [빅데이터] 스파크를 이용한 데이터 셋 탐색 (0) | 2024.06.14 |