🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
진행에 주의 할 점은 이때까지 생성한 데이터를 이용해야한다.
자신의 데이터를 만들어둔 날짜를 변수로 넣는 것을 잊지말자.
Subject2 에 스마트카 운전자 운행 기록 정보를 이용한 Workflow 를 작성 해 본다.
파일 이름 : create_table_smartcar_drive_info_2.hql
create external table if not exists SmartCar_Drive_Info_2 (
r_key string,
r_date string,
car_number string,
speed_pedal string,
break_pedal string,
steer_angle string,
direct_light string,
speed string,
area_number string
)
partitioned by( wrk_date string )
row format delimited
fields terminated by ','
stored as textfile
location '/pilot-pjt/collect/drive-log/'
파일 이름 : insert_table_smartcar_drive_info_2.hql
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table SmartCar_Drive_Info_2 partition(wrk_date)
select
r_key ,
r_date ,
car_number ,
speed_pedal ,
break_pedal ,
steer_angle ,
direct_light ,
speed ,
area_number ,
substring(r_date, 0, 8) as wrk_date
from SmartCar_Drive_Info
where substring(r_date, 0, 8) = '${working_day}';
파일 이름 : create_table_managed_smartcar_drive_info.hql
create table if not exists Managed_SmartCar_Drive_Info (
car_number string,
sex string,
age string,
marriage string,
region string,
job string,
car_capacity string,
car_year string,
car_model string,
speed_pedal string,
break_pedal string,
steer_angle string,
direct_light string,
speed string,
area_number string,
reg_date string
)
partitioned by( biz_date string )
row format delimited
fields terminated by ','
stored as textfile;
Workflow를 다시 추가 해주자
'Subject 2 - Workflow' 라는 이름으로 저장 할 것이다.

매개변수가 필요한 파일은 다음 내용을 넣어주고 저장하자.
working=${today}
예약 파일도 만들어준다.
예약명: Subject 2 - 예약
작업시간: 매일 새벽 3시 30분

해당 작업은 이제 매일 3시 30분 에 실행되어 HBase 에 있는 스마트카 운저나 운행 데이터를 Hive 테이블로 옮기는 작업이다.
바로 확인 해보려면 Workflow 에 매개변수를 20240614 로 변경하여 확인 해 볼 수 있다.

생성된 데이터를 확인 해보자.
select *
from managed_smartcar_status_info
where biz_date = '20240614'
limit 100;
아래 내용은 Subject3 폴더에 저장 할 것이다.
운전패턴이 이상이 있을 경우의 정보를 분석해서 데이터를 생성, 저장한다.
파일 이름 : create_table_managed_smartcar_symptom_info.hql
create table if not exists Managed_SmartCar_Symptom_Info (
car_number string,
speed_p_avg string,
speed_p_symptom string,
break_p_avg string,
break_p_symptom string,
steer_a_cnt string,
steer_p_symptom string,
biz_date string
)
row format delimited
fields terminated by ','
stored as textfile;
파일 이름 : insert_table_managed_smartcar_symptom_info.hql
insert into table Managed_SmartCar_Symptom_Info
select
t1.car_number,
t1.speed_p_avg_by_carnum,
case
when (abs((t1.speed_p_avg_by_carnum - t3.speed_p_avg) / t4.speed_p_std)) > 2
then 'abnormal'
else 'normal'
end
as speed_p_symptom_score,
t1.break_p_avg_by_carnum,
case
when (abs((t1.break_p_avg_by_carnum - t3.break_p_avg) / t4.break_p_std)) > 2
then 'abnormal'
else 'normal'
end
as break_p_symptom_score,
t2.steer_a_count,
case
when (t2.steer_a_count) > 2000
then 'abnormal'
else 'normal'
end
as steer_p_symptom_score,
t1.biz_date
from
(select car_number, biz_date, avg(speed_pedal) as speed_p_avg_by_carnum, avg(break_pedal) as break_p_avg_by_carnum from managed_smartcar_drive_info where biz_date = '${working_day}' group by car_number, biz_date) t1
join
(select car_number, count(*) as steer_a_count from managed_smartcar_drive_info where steer_angle in ('L2','L3','R2','R3') and biz_date = '${working_day}' group by car_number) t2
on
t1.car_number = t2.car_number ,
(select avg(speed_pedal) as speed_p_avg, avg(break_pedal) as break_p_avg from managed_smartcar_drive_info ) t3,
(select stddev_pop(s.speed_p_avg_by_carnum) as speed_p_std, stddev_pop(s.break_p_avg_by_carnum) as break_p_std from
(select car_number, avg(speed_pedal) as speed_p_avg_by_carnum, avg(break_pedal) as break_p_avg_by_carnum from managed_smartcar_drive_info group by car_number) s) t4
매개변수를 넣어주고 저장한다.

Workflow 예약도 해주자.

확인 쿼리
SELECT
car_number,
cast(speed_p_avg as int),
speed_p_symptom,
cast(break_p_avg as float),
break_p_symptom,
cast(steer_a_cnt as int),
steer_p_symptom,
biz_date
FROM managed_smartcar_symptom_info
where biz_date = '20240614'

위를 진행 하던 도중 14일 일자의 데이터가 없어서 데이터가 나오지 않았다.
전체적으로 15일을 기준으로 데이터를 뽑아서 저장 후 도출을 다시 해 보았다.
Subject4 에 만드는 파일은 긴급점검이 필요한 스마트카 정보를 저장하는 쿼리이다.
파일 이름 : create_table_managed_smartcar_emergency_check_info.hql
create table if not exists Managed_SmartCar_Emergency_Check_Info (
car_number string,
tire_check string,
light_check string,
engine_check string,
break_check string,
battery_check string,
biz_date string
)
row format delimited
fields terminated by ','
stored as textfile;
파일 이름 : insert_table_managed_smartcar_emergency_check_info.hql
insert into table Managed_SmartCar_Emergency_Check_Info
select
t1.car_number,
t2.symptom as tire_symptom,
t3.symptom as light_symptom,
t4.symptom as engine_symptom,
t5.symptom as break_symptom,
t6.symptom as battery_symptom,
t1.biz_date
from
(select distinct car_number as car_number, biz_date from managed_smartcar_status_info where biz_date = '${working_day}') t1
left outer join ( select
car_number,
avg(tire_fl) as tire_fl_avg ,
avg(tire_fr) as tire_fr_avg ,
avg(tire_bl) as tire_bl_avg ,
avg(tire_br) as tire_br_avg ,
'Tire Check' as symptom
from managed_smartcar_status_info where biz_date ='${working_day}'
group by car_number
having tire_fl_avg < 80 or tire_fr_avg < 80 or tire_bl_avg < 80 or tire_br_avg < 80 ) t2
on t1.car_number = t2.car_number
left outer join ( select
distinct car_number,
'Light Check' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and (light_fl = '2' or light_fr = '2' or light_bl = '2' or light_br = '2')) t3
on t1.car_number = t3.car_number
left outer join ( select
distinct car_number,
'Engine Check' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and engine = 'C' ) t4
on t1.car_number = t4.car_number
left outer join ( select
distinct car_number,
'Brake Check' as symptom
from managed_smartcar_status_info
where biz_date = '${working_day}' and break = 'C' ) t5
on t1.car_number = t5.car_number
left outer join ( select
car_number,
avg(battery) as battery_avg,
'Battery Check' as symptom
from managed_smartcar_status_info where biz_date = '${working_day}'
group by car_number having battery_avg < 30 ) t6
on t1.car_number = t6.car_number
where t2.symptom is not null or t3.symptom is not null or t4.symptom is not null or t5.symptom is not null or t6.symptom is not null
워크 플로우 작성

예약
이전 날짜의 데이터를 넣어준다. 하루전 데이터는 -1 의 값을 넣어준다.
${coord:formatTime(coord:dateTzOffset(coord:dateOffset(coord:nominalTime(), -2, 'DAY'), "Asia/Seoul"), 'yyyyMMdd')}
Workflow를 실행하고 데이터를 화인 해 본다.
SELECT * FROM managed_smartcar_emergency_check_info WHERE biz_date = '20240615';
Subject 5 는 스마트카 운전자 차량용품 구매 이력 정보를 저장한다.
파일 이름 : create_table_smartcar_item_buylist_info.hql
create table if not exists Managed_SmartCar_Item_BuyList_Info (
car_number string,
sex string,
age string,
marriage string,
region string,
job string,
car_capacity string,
car_year string,
car_model string,
item string,
score string
)
partitioned by( biz_month string )
row format delimited
fields terminated by ','
stored as textfile;
파일 이름 : insert_table_managed_smartcar_item_buylist_info.hql
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table Managed_SmartCar_Item_BuyList_Info partition(biz_month)
select
t1.car_number,
t1.sex,
t1.age,
t1.marriage,
t1.region,
t1.job,
t1.car_capacity,
t1.car_year,
t1.car_model,
t2.item,
t2.score,
t2.month as biz_month
from
SmartCar_Master_Over18 t1 join SmartCar_Item_Buylist t2
on
t1.car_number = t2.car_number
where
t2.month = '202406'
파일 이름 : insert_table_managed_smartcar_item_buylist_info.hql
insert overwrite local directory '/home/pilot-pjt/item-buy-list'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
select car_number, concat_ws("," , collect_set(item))
from managed_smartcar_item_buylist_info
group by car_number
Workflow 작성

예약
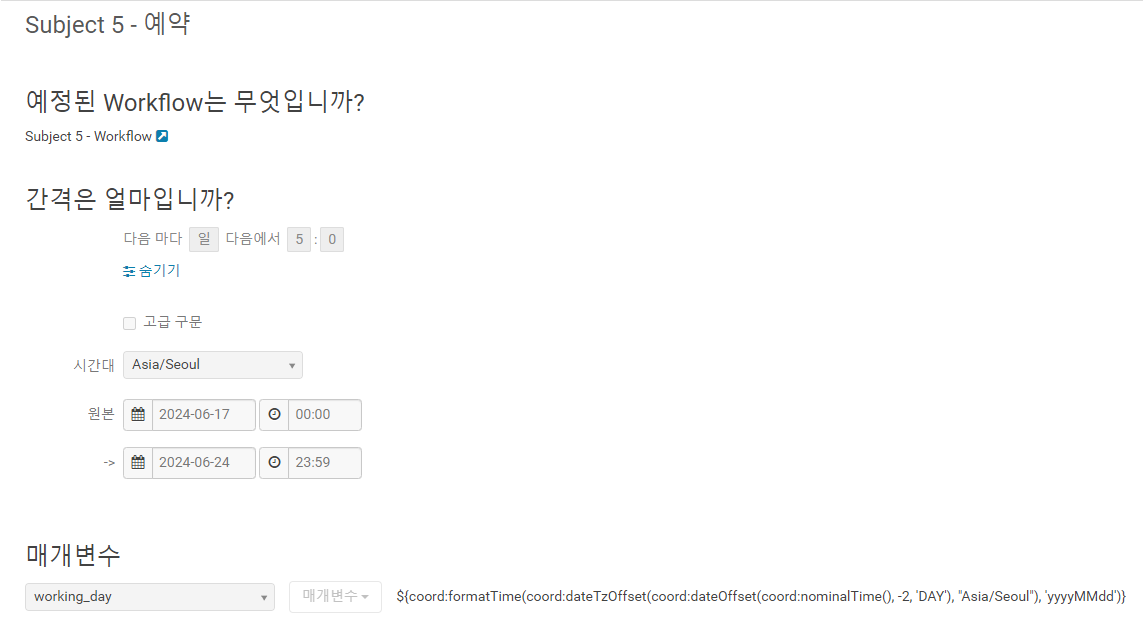
Workflow 실행 및 데이터 확인.
SELECT * FROM managed_smartcar_item_buylist_info WHERE biz_month = '202406';
구매 내력 데이터는' 202406' 일자 데이터를 하는게 아니라
이미 구매 내력이 있는'202003' 데이터를 기준으로 만들고 가져왔다.
'빅데이터' 카테고리의 다른 글
| [빅데이터] Impala 사용해 보기. (2) | 2024.06.18 |
|---|---|
| [빅데이터] 임팔라, 스쿱, 머하웃 설치 With Cloudera, 제플린 설치 With Linux (0) | 2024.06.18 |
| [빅데이터] Oozie 사용 해 보기. (2) | 2024.06.14 |
| [빅데이터] 스파크를 이용한 데이터 셋 탐색 (0) | 2024.06.14 |
| [빅데이터] 문제 풀이 Hive 를 이용한 데이터 탐색 (0) | 2024.06.14 |