🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
이제 리눅스 서버(server02) 로 이동하여 데이터를 생산하여 보자.
cd /home/pilot-pjt/working# 오늘 날짜로 운전자 100개에 대한 데이터를 생성. 백그라운드에서 실행.
java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20240613 100 &
# 오늘 날짜로 차 로그 100개에 대한 데이터를 생성. 백그라운드 실행.
java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.CarLogMain 20240613 100 &
데이터가 생성되는지 Storm 에서 확인.
http://server02.hadoop.com:8088
Topology Summary - Topology Visualization 에서 확인.

대용량 정보는 HBase 로 들어가고
실시간 정보는 Redis 로 들어가는 것을 확인 할 수 있다.
Hue 를 이용하여 데이터 검색
http://server02.hadoop.com:8888
위 주소로 들어가 보자
초기 아이디 비밀번호는 admin / admin 으로 생성 해보자
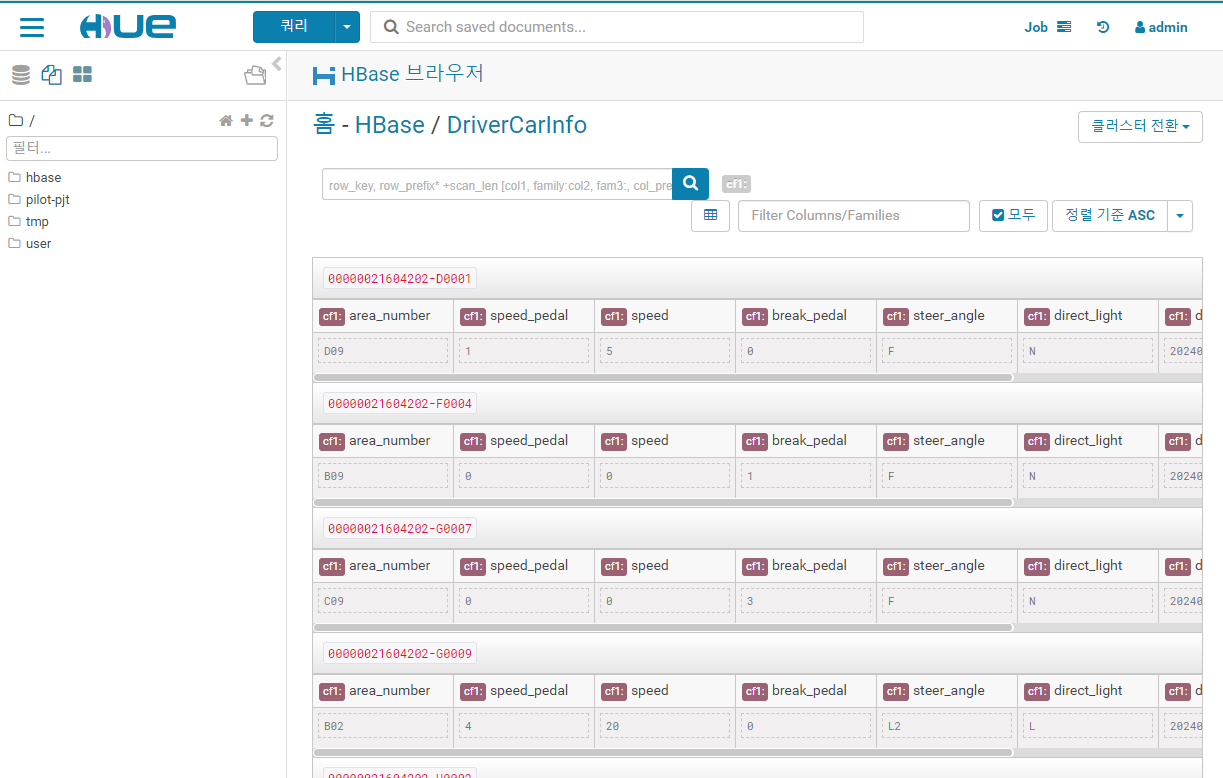
메뉴 - HBase - DriverCarInfo 를 눌러보자
가독성이 좋게 파일을 탐색 할 수 있다.
나오지 않는 사람은
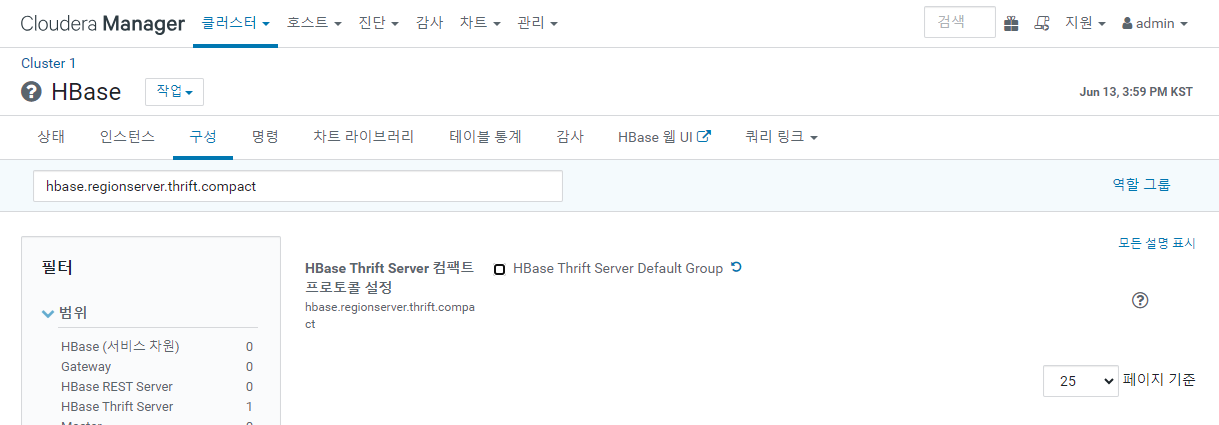
Cloudera Manager 에서 HBase - 구성 - hbase.regionserver.thrift.compact
체크를 해제.
hbase.thrift.support.proxyuser
- 체크

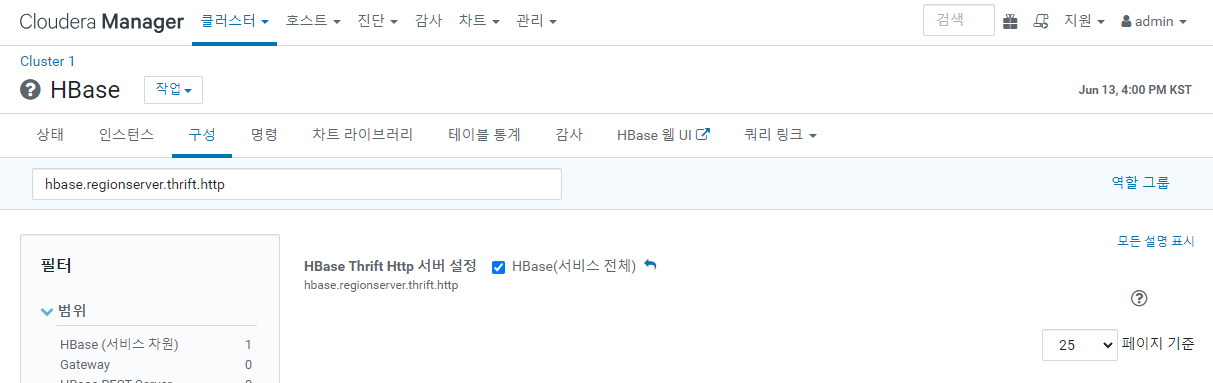
hbase.regionserver.thrift.http
- 체크 확인
core-site.xml에 대한 HBase 서비스 고급 구성 스니펫(안전 밸브)
XML 로 보기 클릭

아래 내용을 입력한다.
<property>
<name>hadoop.proxyuser.hbase.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hbase.groups</name>
<value>*</value>
</property>
이후 내용을 저장 해 주고 재 패포해 주자.
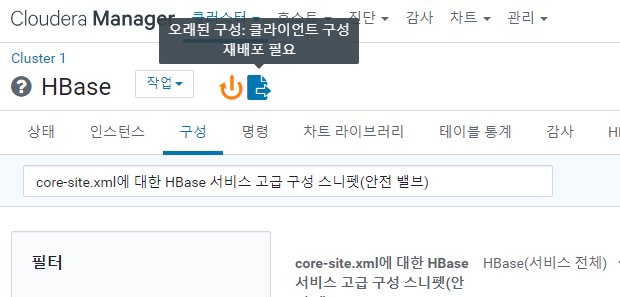
배포 후 HBase, HDFS 를 재시작 해주자.
재 배포 후 안되면 클러스터 재시작, HBase, Spark, Hue 등 모든 시스템을 재시작 해보자.
Hue
쿼리 - 편집기 - Hive
하이브 쿼리는 MySql 쿼리와 비슷하다.
sql 명령문을 4개로 구분된다.
1. DDL(Data Definition Language)
- create,alter,rename,truncate,drop
- commit을 할 필요가 없음
2. DML(Data Manipulation Language)
- select,insert,update,delete
3. DCL(Data Control Language)
- grant(권한주기),revoke(권한회수)
4. TCL(Transaction Control Language)
- commit,rollback,savepoint
hive external table 생성 해 줄 것이다.
create external table if not exists SmartCar_Status_Info (
reg_date string,
car_number string,
tire_fl string,
tire_fr string,
tire_bl string,
tire_br string,
light_fl string,
light_fr string,
light_bl string,
light_br string,
engine string,
break string,
battery string
)
partitioned by( wrk_date string )
row format delimited
fields terminated by ','
stored as textfile
location '/pilot-pjt/collect/car-batch-log/'
작업일자 기준으로 파티션 생성해 보자.
alter table SmartCar_Status_Info
ADD PARTITION(wrk_date='20240612');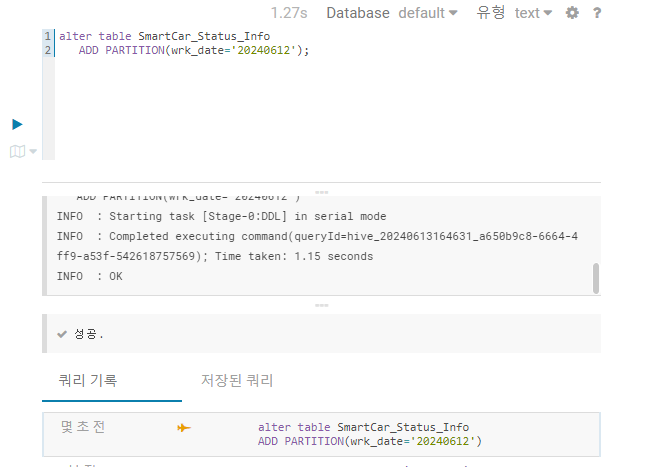
select 를 사용해서 확인 해 볼 수 있다.
select *
from SmartCar_Status_Info
limit 10;
하나 더 실행해 보자.
데이터가 잘 나오는 것을 볼 수 있다.
select car_number,
avg(battery) as battery_avg
from SmartCar_Status_Info
where battery < 60
group by car_number
order by car_number;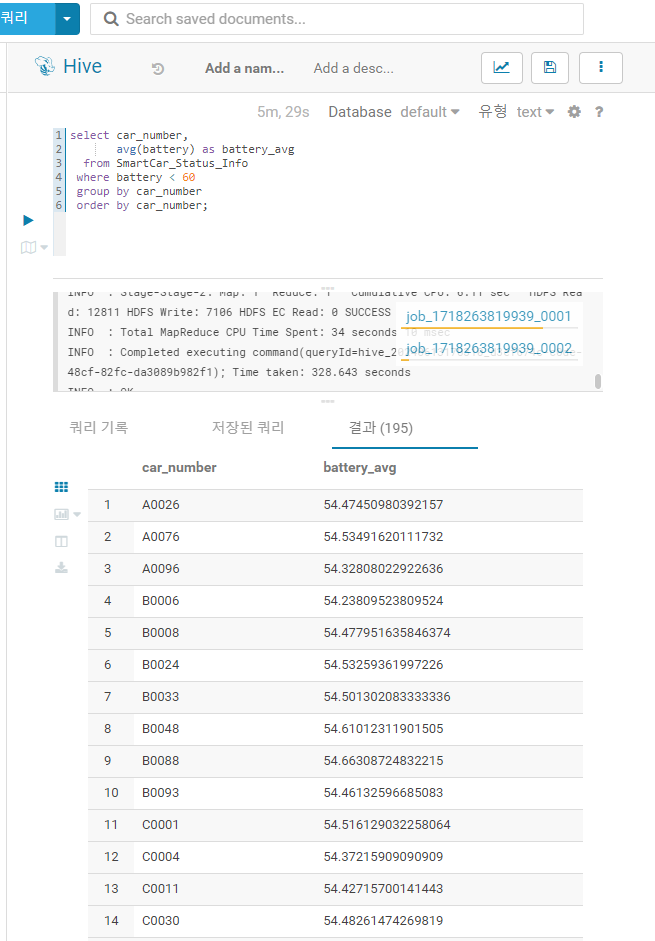
'빅데이터' 카테고리의 다른 글
| [빅데이터] 스파크를 이용한 데이터 셋 탐색 (0) | 2024.06.14 |
|---|---|
| [빅데이터] 문제 풀이 Hive 를 이용한 데이터 탐색 (0) | 2024.06.14 |
| [빅데이터] Cloudera에 Hive, Oozie, Hue, Spark 설치 (0) | 2024.06.13 |
| [빅데이터] Spark 와 Storm 의 차이 (0) | 2024.06.13 |
| [빅데이터] 복습 밑 STS 로 jar 파일 만들기 (0) | 2024.06.13 |