🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
Cloudera Manager에서 Hive를 추가 해 줄 것이다.
클러스터 - 서비스 추가

아래와 같이 설정 해준다.
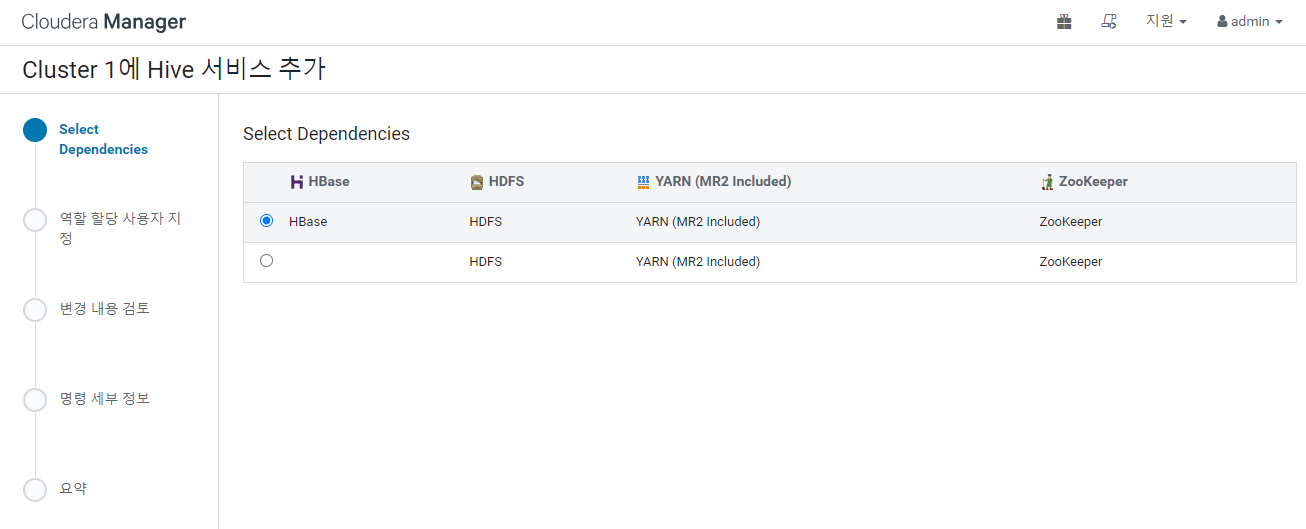
server02 만 선택 WebHCat Server 는 선택하지 않는다.
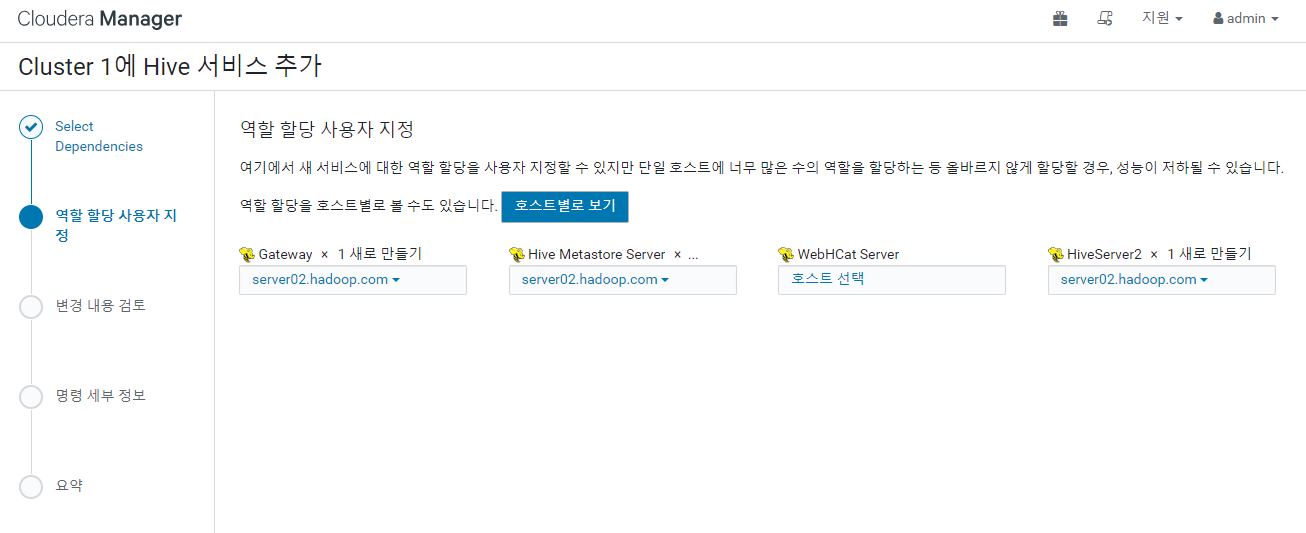
내장 데이터베이스를 사용할 것인데 암호를 복사해서 기억 해두자 ( Fe4uMp4Vu7 )


에러가 날 시 Resume 버튼을 한번 눌러보고
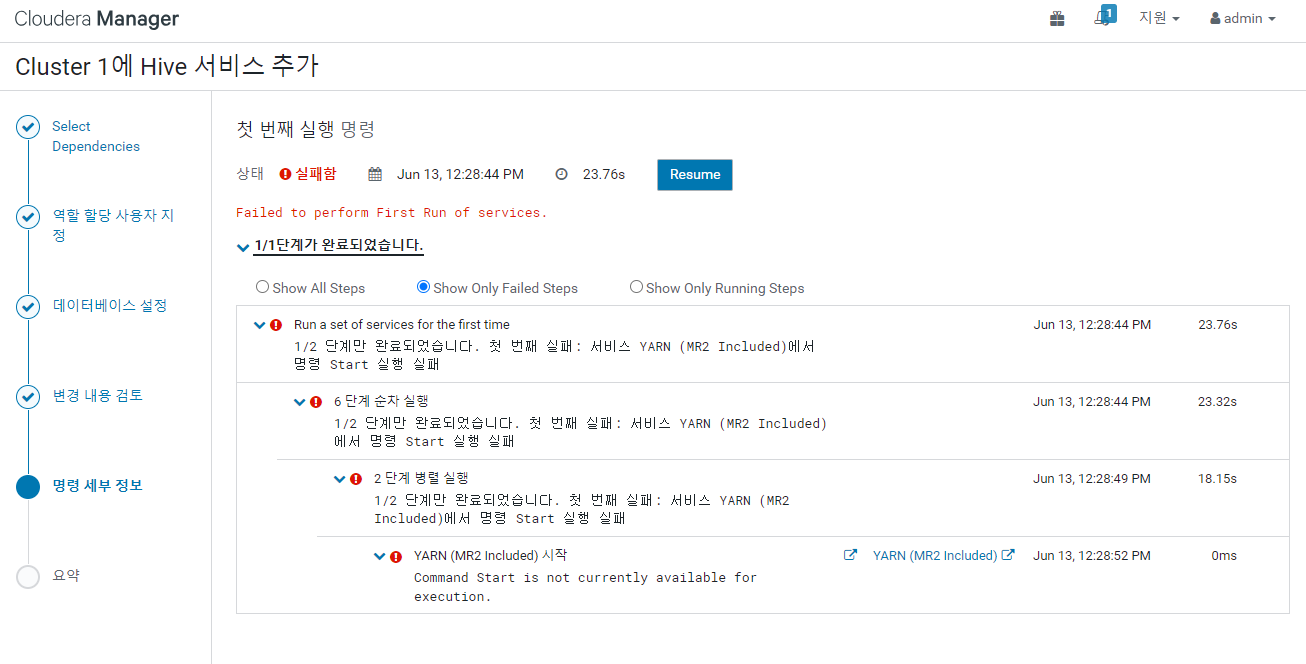
그래도 안된다면 다음과 같이 진행한다.
클라우데라 - HBase - RegionServer 재시작

yarn 도 재시작 해보자

이후 다시 추가를 하려고 하면 다음과 같이 잘 되는 것을 볼 수 있을 것이다.
계속 - 완료를 눌러 추가 해 준다.

우지도 추가 해 주자


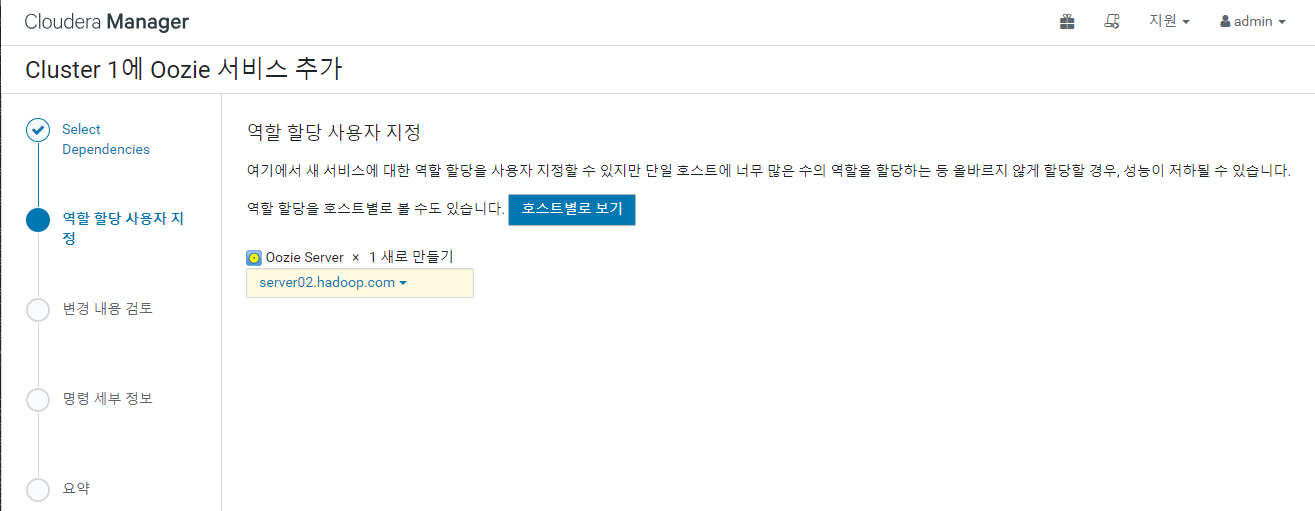
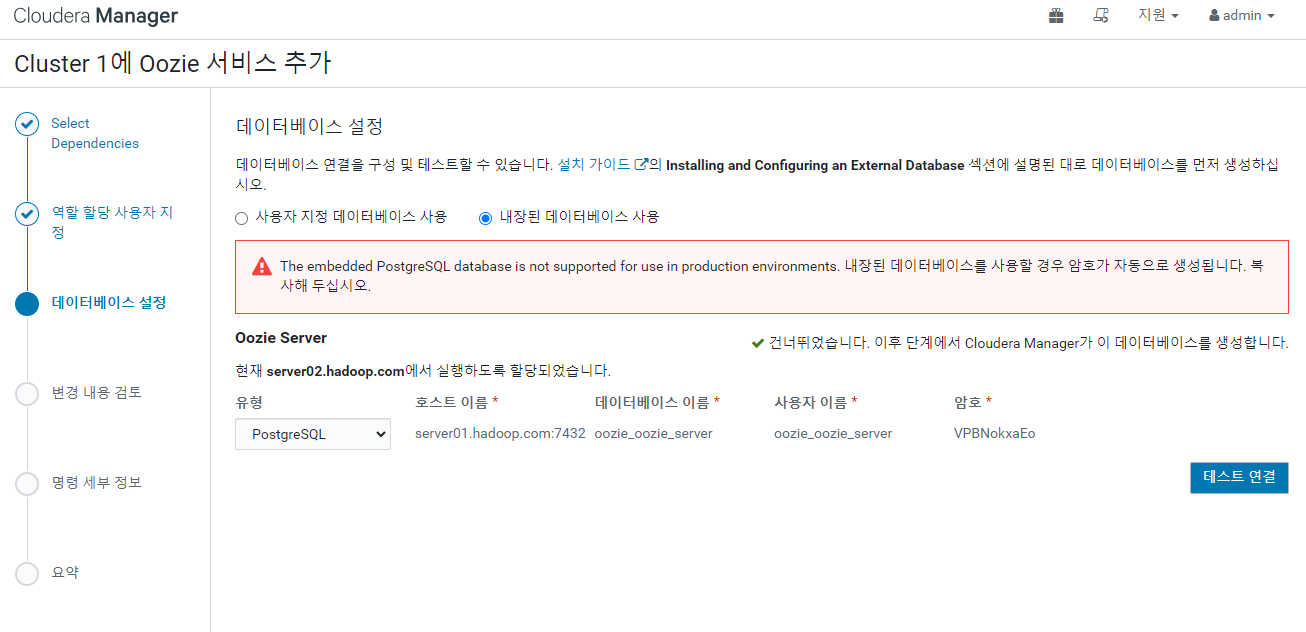
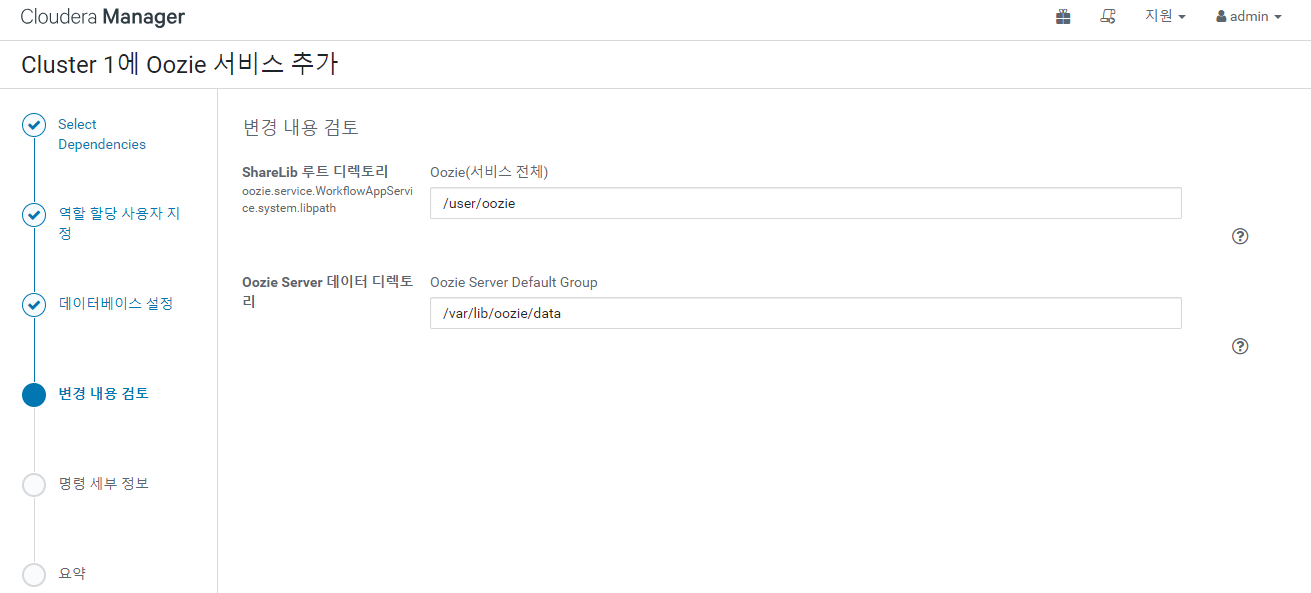

완료 후 우지 - 구성 - Launcher Memory 검색 후 1GB 로 변경 해 주고 우지를 재시작 해준다.

휴 설치
server02 에 아래 네개의 명령문을 실행해서 경로를 변경.
rm /etc/yum.repos.d/cloudera-manager.repo
echo "http://vault.centos.org/6.10/os/x86_64/" > /var/cache/yum/x86_64/6/base/mirrorlist.txt
echo "http://vault.centos.org/6.10/extras/x86_64/" > /var/cache/yum/x86_64/6/extras/mirrorlist.txt
echo "http://vault.centos.org/6.10/updates/x86_64/" > /var/cache/yum/x86_64/6/updates/mirrorlist.txt
Hue 를 사용하려면 Python2.7이 필요해 다운 받아 줄 것이다.
yum install centos-release-scl
위의 명령어를 치고 에러가 난다면 아래 명령어를 쳐주자
echo "http://vault.centos.org/6.10/sclo/x86_64/rh" > /var/cache/yum/x86_64/6/centos-sclo-rh/mirrorlist.txt
echo "http://vault.centos.org/6.10/sclo/x86_64/sclo" > /var/cache/yum/x86_64/6/centos-sclo-sclo/mirrorlist.txt
echo "http://vault.centos.org/6.10/sclo/x86_64/rh" > /var/cache/yum/x86_64/6/centos-sclo-rh/mirrorlist.txt
echo "http://vault.centos.org/6.10/sclo/x86_64/sclo" > /var/cache/yum/x86_64/6/centos-sclo-sclo/mirrorlist.txt
그리고 다시 yum install 명령어를 실행, 에러가 나면 다시 위의 명령어를 쳐준다.
아래 에러 경로에 따른 파일 라인만 입력해 주면되지만 귀찮으니 한번에 다 입력하고 다시 받아주는 것.

다운이 정상적으로 완료되면 다음과 같이 나온다.

이후 아래 명령어를 입력하여 파이썬을 설치해준다.
yum install scl-utils
yum install python27
source /opt/rh/python27/enable
버전을 확인 해보자
python --version
버전이 잘 나오면 파이썬패키지 몇가지를 설치 해 줄 것이다.
yum --enablerepo=extras install epel-release
yum install python-pip
yum install postgresql-devel
bash -c "source /opt/rh/python27/enable; pip install psycopg2==2.6.2 --ignore-installed --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org"
Cloudera Manager 에서 Hue 도 아래와 같이 추가 해 준다.


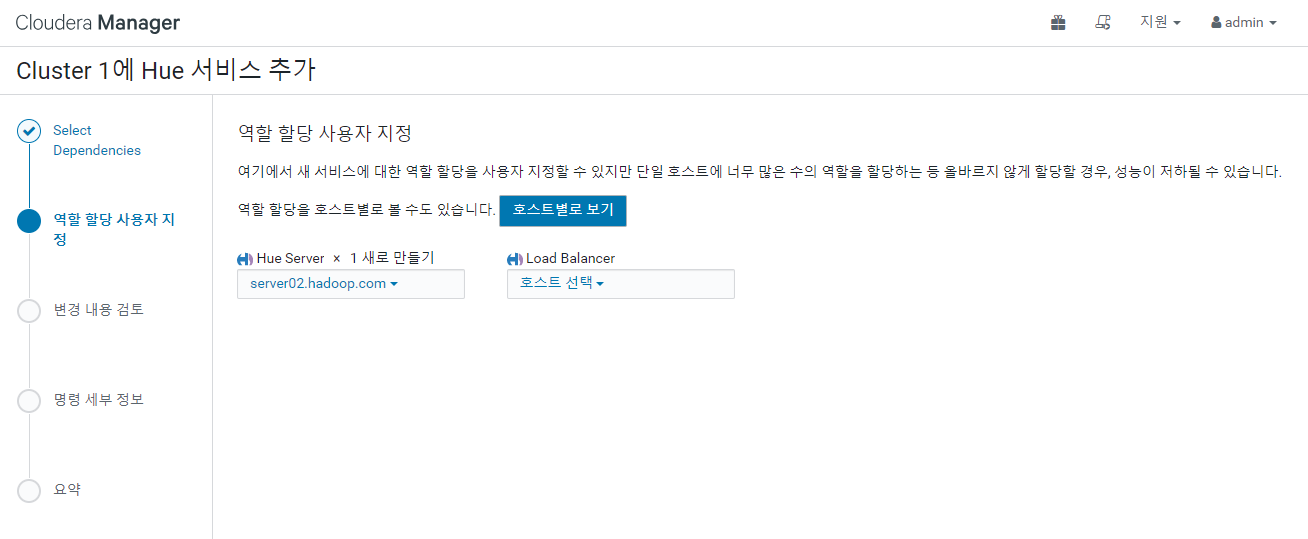

Hue - 구성 - 시간대 - Asia/Seoul 으로 변경

Hue 에서 HBase brower 를 사용 할 수 있는데 옵션을 변경 해 주어야 한다.
HBase Thrift 를 검색 후 선택이 잘 되어있는지 확인.
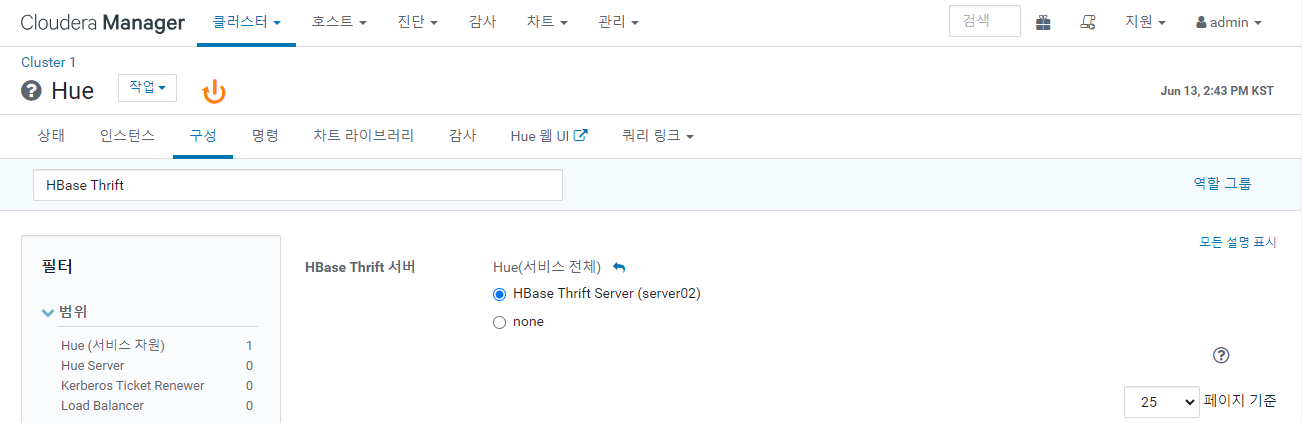
이후 Hue 를 재시작 해주자.
Spark 설치
클러스터 - 서비스 추가




넘겨 주고 설치 후 완료를 눌러주면 끝난다.
이후 YARN 을 재시작, Spark 구성 배포 후 Spark 서비스를 재시작 해준다.

Spark History Server
http://server02.hadoop.com:18088
해당 서버에 접속이 되면 완료된 것이다.

'빅데이터' 카테고리의 다른 글
| [빅데이터] 문제 풀이 Hive 를 이용한 데이터 탐색 (0) | 2024.06.14 |
|---|---|
| [빅데이터] Hue 에서 Hive 명령문 사용. (2) | 2024.06.13 |
| [빅데이터] Spark 와 Storm 의 차이 (0) | 2024.06.13 |
| [빅데이터] 복습 밑 STS 로 jar 파일 만들기 (0) | 2024.06.13 |
| [빅데이터] 실시간 적재 기능 구현 HBase, Redis (1) | 2024.06.12 |