반응형
🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
MobaXterm 을 접속 후 왼쪽 위 Session을 클릭 해준다.
SSH 란으로 들어가서 host 입력(주소)
Specify username 체크(유저 이름 : root)
Port : 22

아래와 같이 뜬다면 접속이 완료 된 것이다.

Cloudera Manager 접속
https://server01.hadoop.com:7180/
다음 주소로 접속하여 클라우데라 매니저에 접속
기본 아이디 비밀번호는 다음과 같다.
아이디 : admin
비밀번호 : admin

설정을 몇가지 해 줄 것이다.
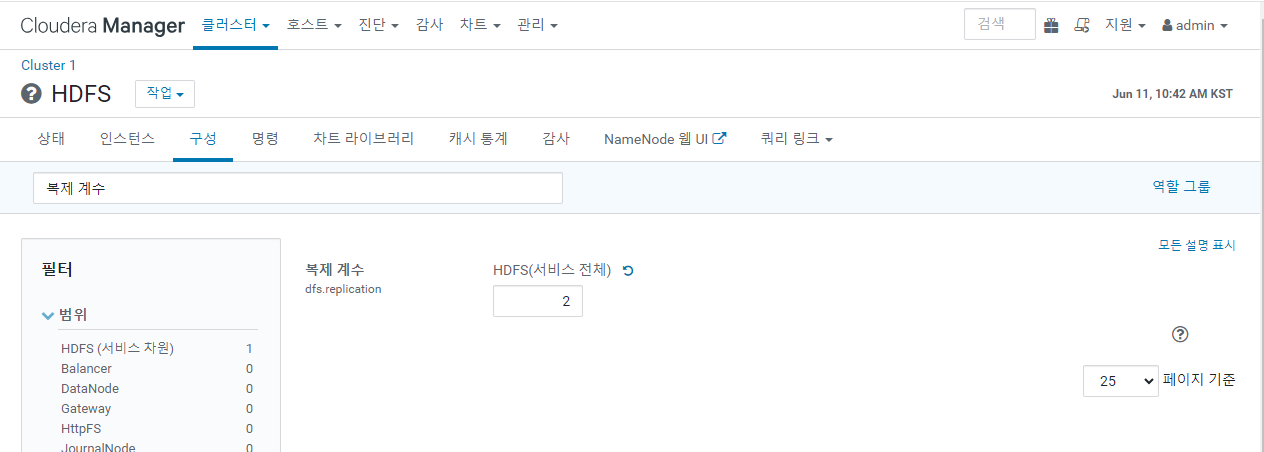
HDFS - 구성

2로 변경 후 변경 내용 저장 클릭.
블록 검색 후 블록 크기도 128MB(기본) -> 64MB 로 변경 해준다.

YARN - 구성 이동.

최대 컨테이너 메모리를 2GB 로 변경 해 준다.

컨테이너 메모리도 5GB로 수정.

schedule 클래스를 FIFO 스케쥴로 변경.

변경 후 클라이언트 구성 재배포 후 클러스터 재시작을 해주자.



클러스터 재시작


'빅데이터' 카테고리의 다른 글
| [빅데이터] jar 파일을 이용한 데이터 처리 및 플럼 설치 (4) | 2024.06.11 |
|---|---|
| [빅데이터] 데이터 파일 업로드 및 시스템 검사. (0) | 2024.06.11 |
| [빅데이터] Virtual Box 서버 추가 및 기본 주소 설정. (에러 발생으로 인한 변경) (0) | 2024.06.11 |
| [빅데이터] 서버 주소 설정 및 Cloudera 설치 (2) | 2024.06.10 |
| [빅데이터] VirtualBox, CentOS 설치 및 설정 (0) | 2024.06.10 |