[빅데이터] 실시간 적재 기능 구현 HBase, Redis
🎁 본 글은 실무로 '배우는 빅데이터기술' 책을 따라해보고 실행하여보는 과정을 기록한 글이다.
🎁 빅데이터 처리의 전체적인 흐름과 과정을 학습하기 쉬우며 빅데이터에 관심있는 사람들에게 추천한다.
HBase 테이블 생성
DriverCarInfo 라는 이름의 테이블을 생성 할 것이다.
hbase org.apache.hadoop.hbase.util.RegionSplitter DriverCarInfo HexStringSplit -c 2 -f cf1
CREATE, Table Name: default:DeiverCarInfo 라는 명령어가 보일 것이다.
테이블 확인은 16010 포트에서 조회 할 수 있다.

파일을 하나 업로드 해 준다.

cd /home/pilot-pjt/working
스톰을 이용하여 배포
storm jar bigdata.smartcar.storm-1.0.jar com.wikibook.bigdata.smartcar.storm.SmartCarDriverTopology DriverCarInfo
다음 메세지가 나오면 완료 된 것이다.
http://server02.hadoop.com:8088/
Topology Summary 에서
DriverCarInfo 이름이 조회 되면 된다.
스마트카 정보 생성을 확인 해보자
cd /home/pilot-pjt/working
java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20240612 10 &
데이터가 제대로 만들어지고 있는지 확인 해본다.
cd /home/pilot-pjt/working/driver-realtime-log
tail -f SmartCarDriverInfo.log
현제 실행된 데이터들은 HBase로 들어가고 있을 것이다 확인 해보자
http://server02.hadoop.com:8088/
Topology Summary 에서
DriverCarInfo 이름을 눌러본다.
Show Visualization 을 클릭한다.


데이터가 쌓이는것을 간략적으로 보여준다.
쉘에 들어가서 데이터들을 확인 할 수 있다.
hbase shell
count 'DriverCarInfo'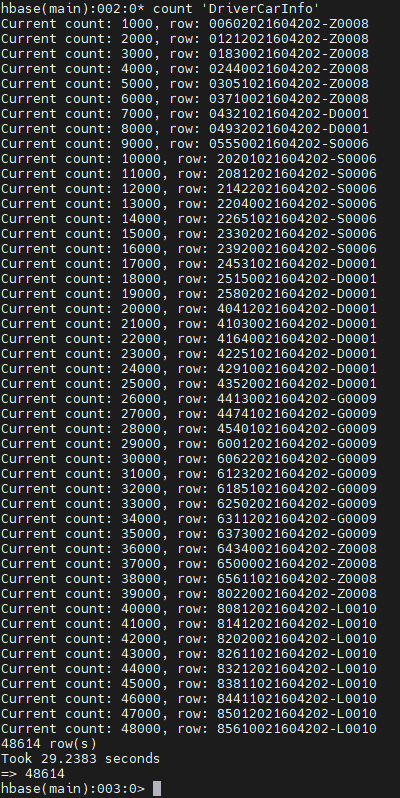
조건을 걸어서 20개의 데이터만 조회 해보자
scan 'DriverCarInfo',{LIMIT=>20}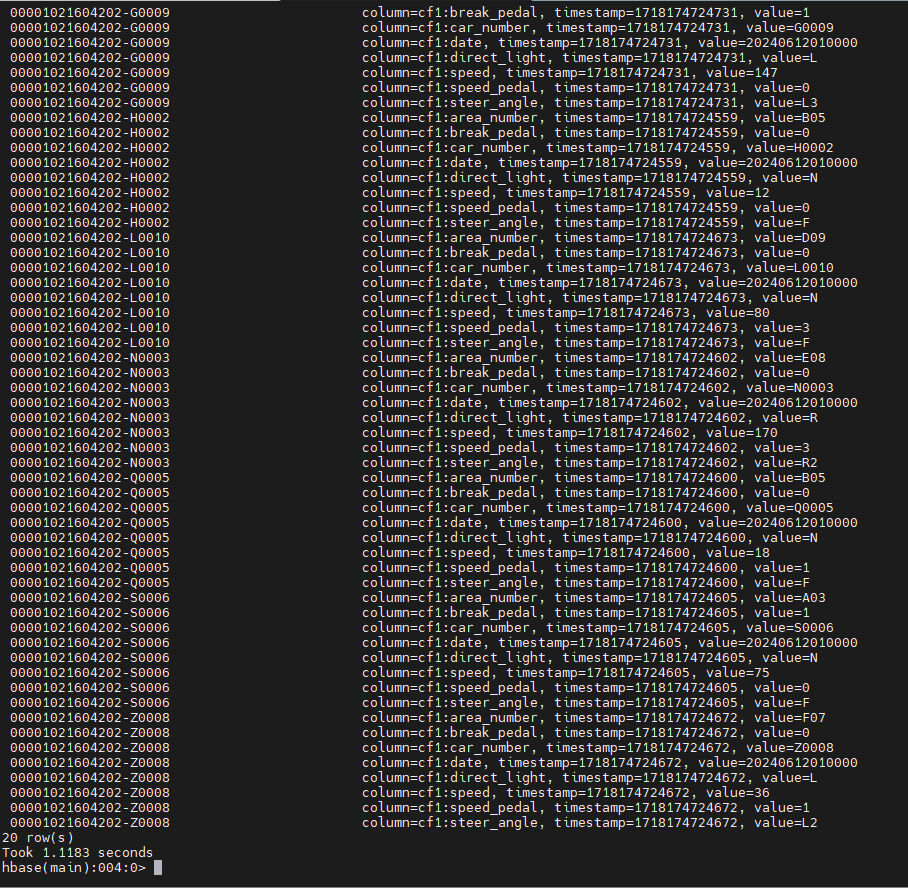
너무 많은 데이터가 쌓이지 않게 프로세스를 정지 할 수도 있다.
ps -ef | grep smartcar.log
kill -9 XX
scan 으로 데이터를 조회하는 방법은 여러가지가 있다.
특정한 번호의 데이터만 조회 해보자
scan 'DriverCarInfo',{STARTROW=>'00001021604202-Z0008',LIMIT=>1}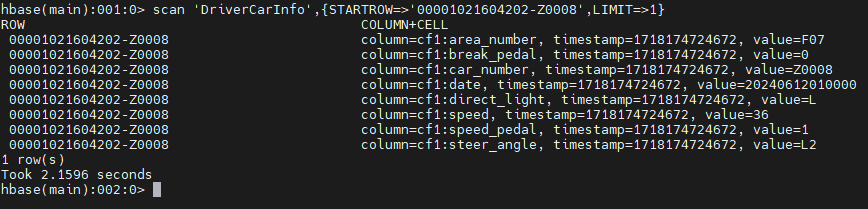
지역번호가 F07 인 지역의 차 운행 정보 중 차 번호와 지역 번호를 가져온다.
scan 'DriverCarInfo',{COLUMNS=>['cf1:car_number','cf1:area_number'],FILTER=>"RowFilter(=,'regexstring:21604202') AND SingleColumnValueFilter('cf1','area_number',=,'regexstring:F07')"}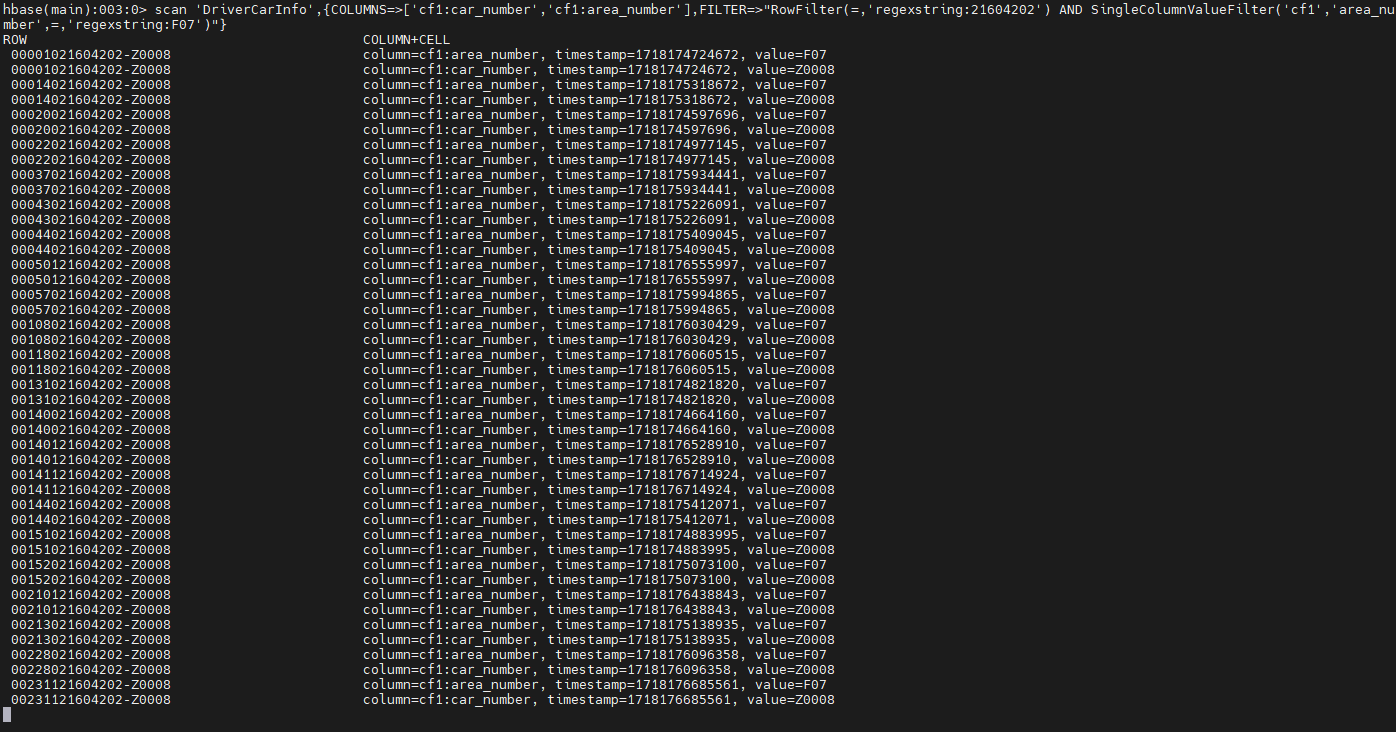
Redis 데이터 확인
redis-cli
smembers 20240612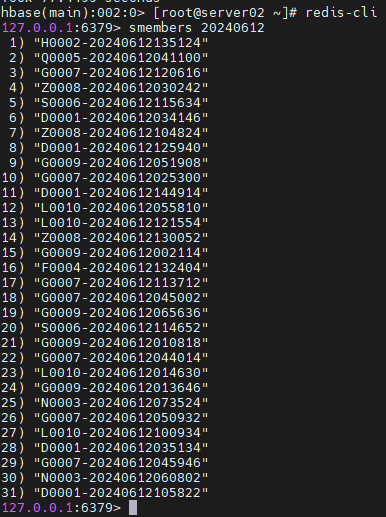
오늘일자 과속 차량 정보를 10초간격으로 가져오는 프로그램을 실행 해 볼 것이다.
Redis 에 사용할 jar 파일을 업로드하자
cd /home/pilot-pjt/working
java -cp bigdata.smartcar.redis-1.0.jar com.wikibook.bigdata.smartcar.redis.OverSpeedCarInfo 20240612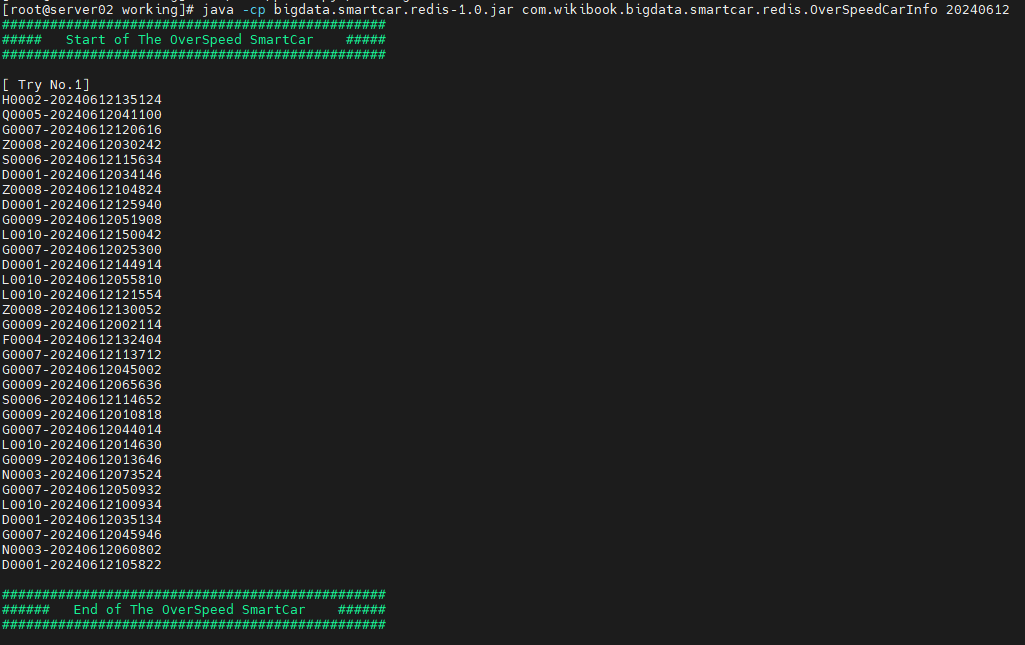
다음과 같이 실시간 정보를 10초 간격으로 계속 가져온다.